Details
-
Improvement
-
Status: Open
-
 Normal
Normal
-
Resolution: Unresolved
-
13.4.17, 14.7.6, 15.0.0
-
None
-
None
-
Orion
-
BrXM Backlog
Description
Reported by client,
They have a setup, with 2 beefed up servers, 24 GB of heap each.
After upgrade to v14 last month, they also increased Tomcat thread count because of introduction of one of the services, which was/is expected to be slow (crunching and fetching big chunk of data). Increasing tomcat thread/connection count didn't help, as they didn't know of HST session limit which was still configured with default value (100 for live sessions).
After bumping HST session count, situation improved but not always: in cases where nr. of clients suddenly increased, they noticed some slowdown when session from the session pool needed to be created/activated.
Below are their findings (and their workaround: keeping number of active sessions high/longer).
Maybe we can improve on this, but I am not familiar with the code.
====================== CLIENT REPORT:
After multiple profiling sessions made in the production server using NewRelic APM and JavaFlightRecorder (Java Mission Control) we identified serious thread contention (blocking) problems caused by the JCR session creation code. The issue begins in the transition from low concurrent JCR access to high concurrent JCR access which forces the JCR pool to grow quickly.
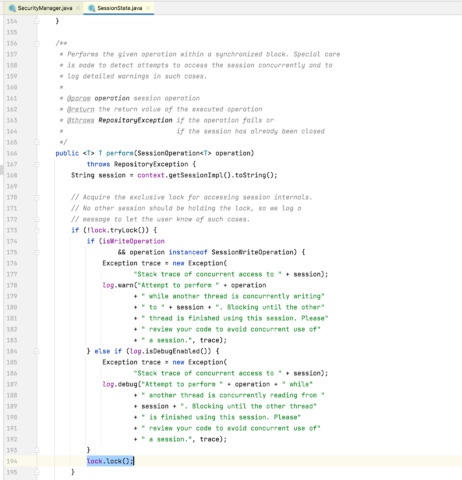
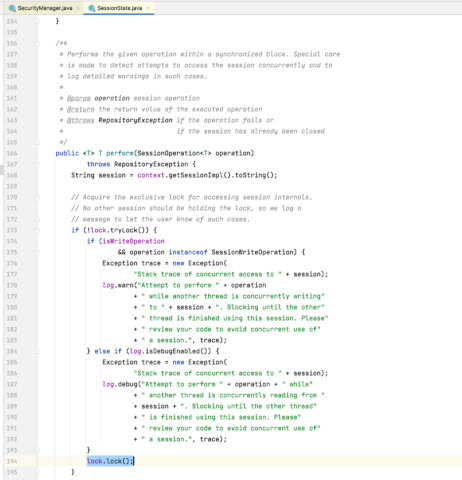
We identified that multiple threads were waiting for a lock release in the following stacktrace (some lines removed for better readability) :
stackTrace: java.lang.Thread.State: WAITING (parking) at sun.misc.Unsafe.park(Native Method) - parking to wait for <0x00000001bf6161b8> (a java.util.concurrent.locks.ReentrantLock$NonfairSync) at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175) ... at java.util.concurrent.locks.ReentrantLock.lock(ReentrantLock.java:285) at org.apache.jackrabbit.core.session.SessionState.perform(SessionState.java:194) at org.apache.jackrabbit.core.query.QueryManagerImpl.perform(QueryManagerImpl.java:197) at org.apache.jackrabbit.core.query.QueryManagerImpl.createQuery(QueryManagerImpl.java:91) at org.hippoecm.repository.security.SecurityManager.getDomains(SecurityManager.java:368) ... at org.hippoecm.hst.core.jcr.pool.BasicPoolingRepository$SessionFactory.makeObject(BasicPoolingRepository.java:1126) at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:1188) at org.hippoecm.hst.core.jcr.pool.BasicPoolingRepository.login(BasicPoolingRepository.java:342) ... at org.hippoecm.hst.core.jcr.pool.MultipleRepositoryImpl.login(MultipleRepositoryImpl.java:173) at org.hippoecm.hst.site.request.HstRequestContextImpl.getSession(HstRequestContextImpl.java:229) ... at org.hippoecm.hst.site.request.ResolvedSiteMapItemImpl.resolveComponentConfiguration(ResolvedSiteMapItemImpl.java:197) at org.hippoecm.hst.site.request.ResolvedSiteMapItemImpl.getHstComponentConfiguration(ResolvedSiteMapItemImpl.java:126) ... at org.hippoecm.hst.container.HstDelegateeFilterBean.processResolvedSiteMapItem(HstDelegateeFilterBean.java:1022) at org.hippoecm.hst.container.HstDelegateeFilterBean.doFilter(HstDelegateeFilterBean.java:579) at org.hippoecm.hst.container.DelegatingFilter.doFilter(DelegatingFilter.java:68) at org.hippoecm.hst.container.HstFilter.doFilter(HstFilter.java:51) ...
The most important parts are the following:
Borrow a JCR session object from the pool that forces the pool to create a new JCR session object (idle sessions < maxActive):
org.hippoecm.hst.core.jcr.pool.BasicPoolingRepository$SessionFactory.makeObject(BasicPoolingRepository.java:1126) at org.apache.commons.pool.impl.GenericObjectPool.borrowObject(GenericObjectPool.java:1188)
Hippo JCR session creation code queries the JCR repository using a single shared JCR session along all threads (systemSession):
org.hippoecm.repository.security.SecurityManager.getDomains(SecurityManager.java:368)
JCR session objects are not thread-safe. The systemSession JCR object is shared with all threads that need to create a new JCR session object in the pool at a given time. So, in case of peak demand for JCR access (most Hippo HTTP requests need to query the JCR) and having the pool with idle sessions low, the Hippo pool provisioning code causes high contention and high response times for all new requests arriving while new JCR sessions are created 1 by 1 due to the existing lock at the mentioned Hippo pool provisioning code.
We have deployed a workaround pre-provisioning JCR session objects in all JCR pools. For example:
# Default Session Pool Configuration for 'live'. default.repository.maxActive = 600 default.repository.maxIdle = 600 default.repository.minIdle = 400 default.repository.initialSize = 400 default.repository.numTestsPerEvictionRun = 5
Increasing the initialSize and the minIdle values we reduce the probability of creating new instances on the pool. By increasing the maxIdle and making it equal to the maxActive we avoid destroying JCR sessions too early.
As mentioned previously, we think this is only a workaround in order to avoid a bug in Hippo. We think that creating new JCR session objects should not be synchronized.